

ChatGPTが提供する知識は、どこから来ているのでしょうか?多くの人々が日々使用するChatGPTですが、その背後にある技術的な仕組みや、どのようにして幅広い知識が組み込まれているのかはあまり知られていません。この記事では、ChatGPTの情報源を明らかにし、AIがどのようにしてあなたの質問に答える能力を得ているのかを解説します。知識の起源を理解することで、生成AIをより賢く、また安全に活用することができるようになります。
WithAIメールマガジン登録(無料)
WithAIメールマガジンでは、生成AIの活用事例や、最新Newsから今すぐ使える実践ノウハウまで、
Webサイトではお届けしきれないさまざまなお役立ち情報を配信しています。ぜひご登録ください。
ChatGPTの情報源はどこから?
ChatGPTの情報源は、インターネット上の多岐にわたる公開データから収集されています。具体的には、以下のようなソースが含まれます。
- 書籍:さまざまなジャンルやトピックの書籍からのテキスト。
- ソーシャルメディア:TwitterやFacebookなどのソーシャルメディアプラットフォームからの投稿やコメント。
- Wikipedia:多言語の百科事典Wikipediaの記事。
- ニュース記事:多様なニュースソースからのニュース記事。
- スピーチと音声録音:音声データをテキストに変換したもの。
- 学術研究論文:科学的および学術的なジャーナルや出版物からのテキスト。
- ウェブサイト:ブログや企業のウェブサイトなど、インターネット上のさまざまなウェブサイトのコンテンツ。
- フォーラム:RedditやQuoraなどのオンラインフォーラムやメッセージボードでの議論。
- コードリポジトリ:GitHubなどのオンラインコードリポジトリからのテキストやコードスニペット。
ChatGPTのトレーニングは、以下の2つのフェーズで行われます
1. プレトレーニング
このフェーズでは、インターネット上の公開テキストの大規模なコーパスを使用して言語モデルがトレーニングされます。具体的なデータソースやその量については公開されていませんが、これは過学習や悪用を防ぐためです。
- コーパスとは?
- コーパスとは、言語研究や自然言語処理に使用される大規模なテキストデータの集合のことです。
2. ファインチューニング
プレトレーニング後、OpenAIが作成したカスタムデータセットを使用してモデルがファインチューニングされます。これには、正しい動作のデモンストレーションや異なる応答をランク付けする比較が含まれます。ファインチューニングの一部のプロンプトは、ChatGPTプラットフォーム上でのユーザーとの対話から得られることもありますが、個人情報や個人を特定できる情報は削除されます。
- ファインチューニングとは?
- ファインチューニングとは、事前学習済みの大規模言語モデル(LLM)を特定のタスクや領域に適応させるために追加で学習させるプロセスです。
これらのデータソースとトレーニングプロセスにより、ChatGPTは多様なトピックに関する情報を提供できるようになっていますが、特定の情報源を正確に引用することはできません。また、トレーニングデータは2023年までのものであり、それ以降の出来事については知識が限られています。
このように、ChatGPTは広範なデータソースから学習し、ユーザーの質問に対して人間らしい応答を生成する能力を持っていますが、常に正確な情報を提供するわけではないため、重要な情報は信頼できるソースで確認することが重要です。
ChatGPT活用ノウハウ3点セットでは、ChatGPTを活用する上でのリスクや注意すべきこと、お役立ちテンプレートなど役立つ情報を余すことなく解説しています。ぜひダウンロードしてご活用ください。

ChatGPTのチャット履歴を無効にする方法は?
ChatGPTのチャット履歴を無効にする方法は以下の通りです
1.ChatGPTにログインします。
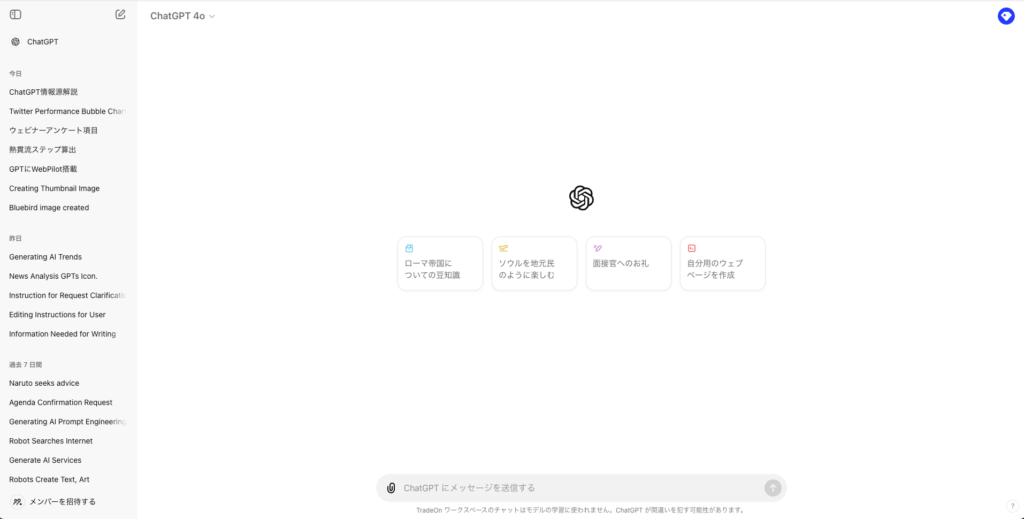
2.画面左下のプロフィールアイコンをクリックし、「設定」を選択します。
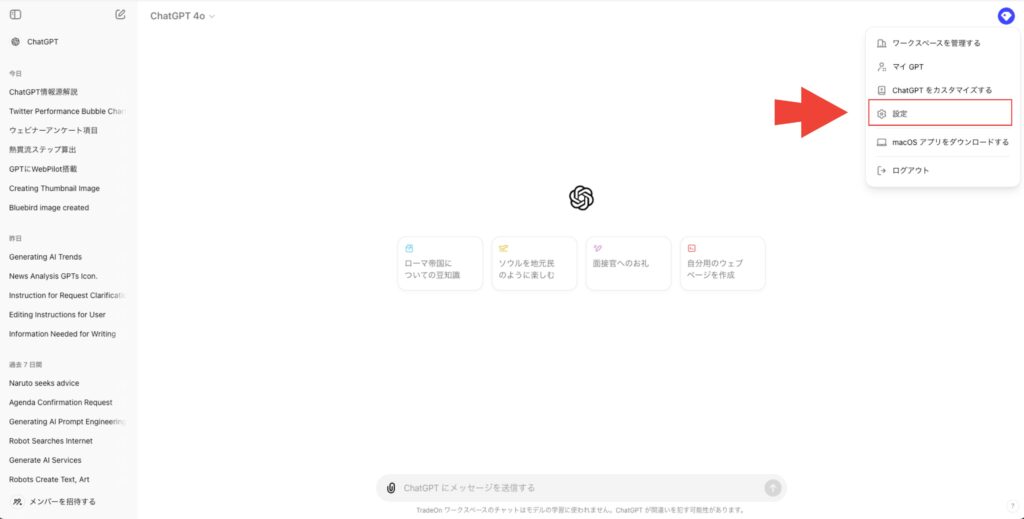
3.設定画面で「データコントロール」セクションを探します。
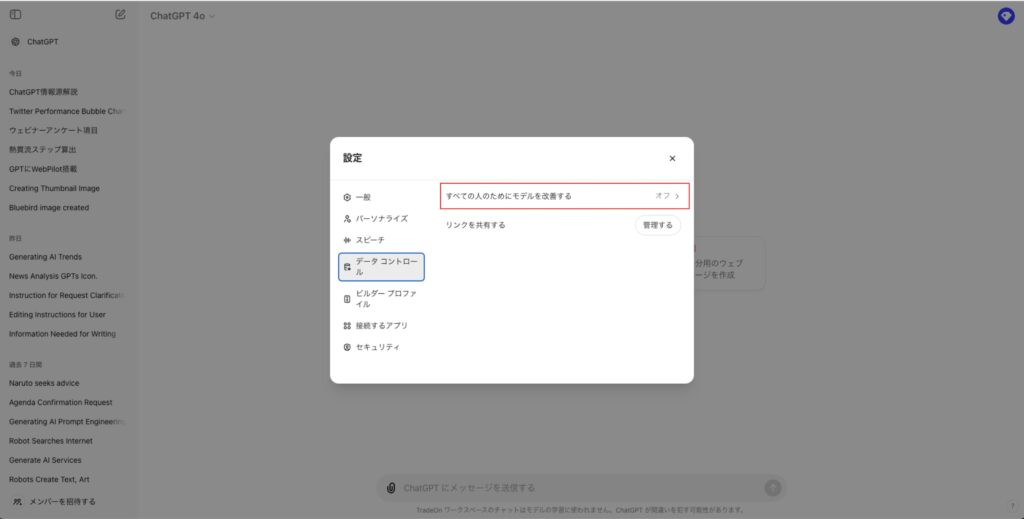
4.「チャット履歴と学習」または「モデルの改善に協力する」というオプションを見つけ、トグルをオフにします。
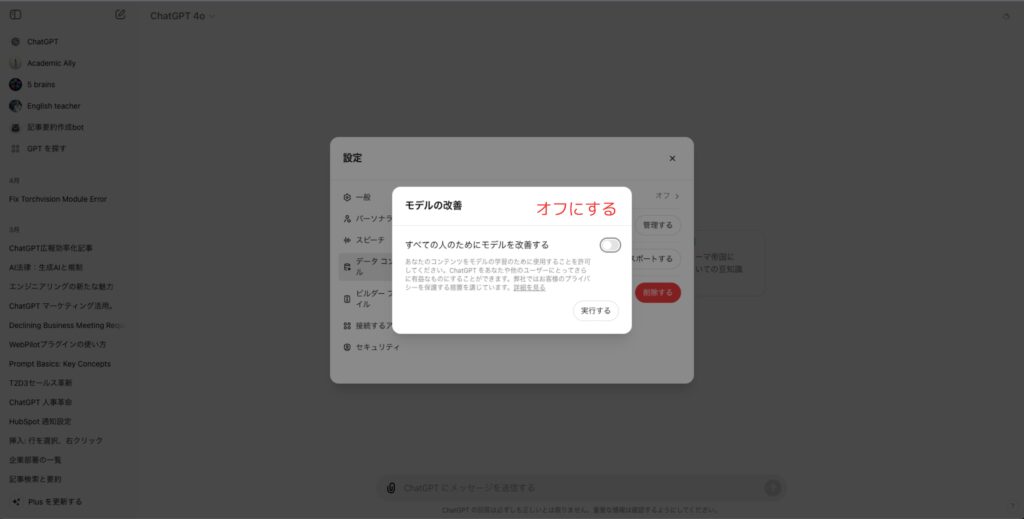
この設定を無効にすると、以下の効果があります:
- 新しい会話がOpenAIのモデル学習に使用されなくなります。
- 会話履歴がサイドバーに表示されなくなります。
- ただし、OpenAIは不正利用の監視のために30日間データを保持します。その後、完全に削除されます。
この設定は、ウェブ版とモバイルアプリの両方で同期されます。
過去の会話履歴は保持されますが、グレーアウトされて表示されます。
一時的なチャットオプションも利用可能で、これを使うと会話が保存されません。
プライバシーを重視する場合は、この設定を無効にすることをお勧めします。ただし、機密情報や個人情報の入力は引き続き避けるべきです。
ChatGPTのトレーニングデータの量はどれくらい?
ChatGPTのトレーニングデータの量については、いくつかの異なる情報源からのデータがありますが、以下のように言われています。
GPT-3のトレーニングデータ:
GPT-3は、約45テラバイト(TB)の圧縮プレーンテキストデータを使用してトレーニングされました。このデータは、インターネット上のさまざまなソースから収集されました。
フィルタリング後のデータ量は約570ギガバイト(GB)です。
GPT-4のトレーニングデータ:
GPT-4のトレーニングデータの正確な量は公開されていませんが、GPT-3のデータ量を大幅に上回るとされています。GPT-4は、GPT-3の約5倍のパラメータ(100兆パラメータ)を持つと推定されています。
これらのデータ量は、モデルが多様なテキストデータから学習し、自然な言語生成能力を持つために必要な大規模なデータセットを反映しています。トレーニングデータには、書籍、記事、ウェブページ、Wikipediaなどのさまざまなソースが含まれています。
ChatGPTのデータはどのようにプライバシーに反する可能性があるのか

ChatGPTのデータ利用には、以下のようなプライバシーに関する懸念点があります:
1.個人情報の収集と保存:
ユーザーとの会話内容や入力された情報が、OpenAIのサーバーに保存される可能性があります。
これには機密情報や個人を特定できる情報が含まれる可能性があります。
2.データの使用目的の不透明性:
収集されたデータがどのように使用されるのか、ユーザーに十分な説明がなされていない可能性があります。
AIモデルの改善や学習に使用される可能性がありますが、その範囲が明確ではありません。
3.同意の問題:
ユーザーが自分のデータがどのように使用されるかについて、十分な情報を得た上での同意を与えていない可能性があります。
4.未成年者のデータ保護:
年齢確認システムがないため、未成年者のデータが不適切に収集・使用される可能性があります
5.「忘れられる権利」の実現困難:
AIモデルの学習に使用されたデータを完全に削除することが技術的に困難である可能性があります。
6.データ漏洩のリスク:
サイバーセキュリティ上の脆弱性により、保存されたデータが漏洩するリスクがあります。
7.第三者との情報共有:
OpenAIが収集したデータを第三者と共有する可能性があります。
8.プロファイリングの懸念:
収集されたデータを基に、ユーザーのプロファイリングが行われる可能性があります。
これらの懸念点は、EUのGDPRなどのデータ保護法に抵触する可能性があり、実際にイタリアなどでは一時的に利用が禁止されるなどの措置が取られました。プライバシー保護と革新的なAI技術の利用のバランスを取ることが今後の課題となっています。
ChatGPTのデータが他のユーザーに使われるリスクは?
ChatGPTのデータが他のユーザーに使われるリスクについて、以下のような懸念点があります:
1.データの漏洩と不正利用:
ChatGPTに入力された情報が、OpenAIのサーバーに保存され、他のユーザーや第三者に漏洩するリスクがあります。
機密情報や個人を特定できる情報が含まれている可能性があり、それが悪用される恐れがあります。
2.プライバシーの侵害:
ユーザーの会話履歴や入力データが、本人の同意なしに他の目的で使用される可能性があります。
個人情報が含まれたデータが、ChatGPTの学習に使用され、他のユーザーの質問に対する回答に反映される恐れがあります。
3.セキュリティリスク:
ChatGPTのプラグインやカスタムGPTを通じて、悪意のある第三者がユーザーデータにアクセスする可能性があります。
サイバー犯罪者がChatGPTを利用して、フィッシング攻撃やマルウェア開発に利用するリスクがあります。
4.コンプライアンス違反:
ユーザーデータの収集と使用が、GDPRなどのデータ保護法に違反する可能性があります。
企業の機密情報や顧客データが不適切に扱われ、法的問題を引き起こす恐れがあります。
これらのリスクを軽減するために、以下のような対策が推奨されます:
- ChatGPTに機密情報や個人情報を入力しない。
- 企業はChatGPTの使用に関するポリシーを策定し、従業員に教育を行う。
- データ暗号化やアクセス制御などのセキュリティ対策を実施する。
- ChatGPTの使用状況を監視し、定期的にリスク評価を行う。
ChatGPTの利便性は高いものの、データセキュリティとプライバシー保護の観点から慎重な利用が求められます。
正しく活用すれば、安全に活用できる!
ChatGPTは膨大な情報源から知識を収集し、私たちの日常生活や業務を支援しますが、安全に活用するためにはいくつかのポイントを押さえておくことが重要です。
1. 情報の確認:
ChatGPTの回答は他の信頼できる情報源で確認しましょう。AIは時折誤った情報を提供することがあるため、特に重要な決定を下す際には複数のソースを参照することが賢明です。
2. プライバシー保護:
ChatGPTに個人情報や機密情報を入力しないように注意しましょう。プライバシーの保護は常に最優先事項であり、AIとのやり取りでもその点を忘れずに意識することが大切です。
3. 正しい設定:
この記事で扱ったような設定方法で、情報を学習に利用されないようにすることが大切です。
4. 適切な用途での利用:
ChatGPTはあくまで補助ツールとして利用しましょう。専門的な知識や複雑な問題解決には、最終確認として人間が関わるようにしましょう。
結論:
ChatGPTの情報源とその活用方法を理解することで、このAIを安全かつ効果的に利用することができます。知識を確認し、プライバシーを守り、正しい設定を行うことで、ChatGPTは信頼できるパートナーとしてあなたをサポートします。


