

2023年12月、Googleは最新のマルチモーダル生成AIモデル「Gemini」を公開して大きな話題を呼びました。ただ、「Geminiって聞いたことあるけど何ができるのかわからない」、「ChatGPTとの違いは?」という疑問をお持ちの方も多いのではないでしょうか?
この記事は、Googleの「Gemini」とはなにか?、どれくらいの性能なのか、他の生成AIとの違いをわかりやすく解説します。
WithAIメールマガジン登録(無料)
WithAIメールマガジンでは、生成AIの活用事例や、最新Newsから今すぐ使える実践ノウハウまで、
Webサイトではお届けしきれないさまざまなお役立ち情報を配信しています。ぜひご登録ください。
Googleの最新マルチモーダルAI「Gemini」とは?

Gemini(ジェミニ)は、Googleが2023年12月に発表した高機能生成AIモデルです。このAIモデルは、テキスト、画像、音声、動画などの多様なデータ形式を処理する能力を持つ「マルチモーダル」AIとして設計されています。
Geminiの主な特徴
マルチモーダル処理
Geminiは、テキスト、画像、音声、動画などの異なるデータ形式を同時に処理することができます。これにより、複雑な文脈やニュアンスを理解し、より正確な情報を提供することが可能です。
高度な推論能力
Geminiは膨大なデータから難解な知識を発見し、高度な推論を行う能力に優れています。これにより、科学や金融などの分野での研究や調査が加速することが期待されています。
高品質なコード生成
プログラミングコードの自動生成も可能で、自然言語での指示に基づいて高品質なコードを生成することができます。
Geminiのモデルバリエーション

Geminiには、用途や精度に応じて以下の3つのモデルが用意されています。
- Gemini Ultra: 最も高精度なモデルで、ビジネス向けの有料プランで提供されます。
- Gemini Pro: 汎用モデルで、無料のAIチャットやスマホアプリなどで利用可能です。
- Gemini Nano: スマホなどの端末内でAIの処理を完結させる「オンデバイス」モデルです。
利用方法と活用事例
Geminiは、以下のような多岐にわたる用途で利用可能です。
- 文章の作成、要約、翻訳
- 校正、編集
- 論文や数学問題の解説
- プログラミングコードの自動生成
- 画像認識と内容の解説
- 音声入力と画像生成
- Googleアプリとの連携(例:Googleドキュメント、Google Maps)
他のAIモデルとの違い
Geminiは、他のAIモデルと比較して以下の点で優れています。
- 自然言語処理の能力: 複雑な文脈やニュアンスの理解度が高い。
- 学習と進化の速度: 高速で進化し続ける能力。
- 応用可能なジャンルや分野: 幅広い分野での応用が可能。
まとめ
Geminiは、Googleが提供する最新の生成AIモデルであり、そのマルチモーダル処理能力と高度な推論能力により、さまざまな分野での利用が期待されています。特に、テキスト、画像、音声、動画を同時に処理できる点が大きな特徴であり、ビジネスや研究の生産性向上に寄与することが期待されています。
Geminiの料金はどれくらい?
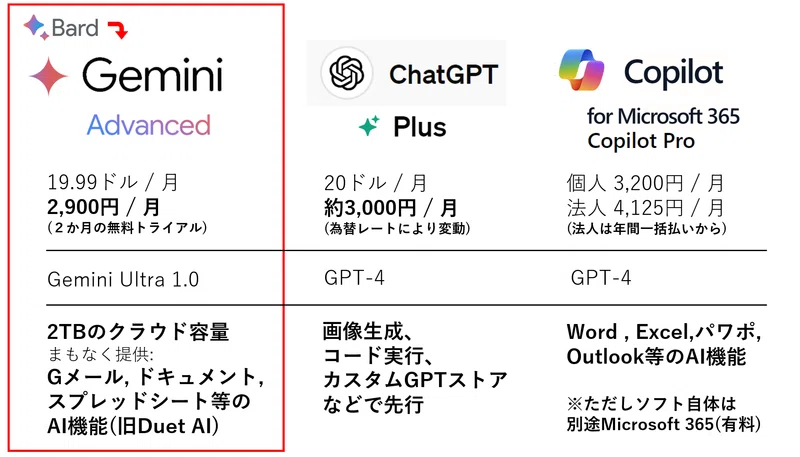
Geminiの料金体系について、以下のようにまとめることができます
Gemini Pro (無料版):
無料で利用可能
Google Bardなどの無料サービスで使用されている
Gemini Advanced (Ultra 1.0モデル):
Google One AI Premiumプランの一部として提供
月額2,900円(約$20/月)
2TBのGoogle Driveストレージなど他の特典も含む
Gemini API (開発者向け):
Gemini Pro API:
入力: $0.00025 / 1,000文字
出力: $0.0005 / 1,000文字
画像入力: $0.0025 / 画像
動画入力: $0.002 / 秒
Gemini Ultra API (現時点で未公開):
料金は未発表
Gemini 1.5 Pro API:
入力: $3.50 / 100万トークン (128Kトークンまでのプロンプト)
出力: $10.50 / 100万トークン
Gemini Nano:
Google Pixel 8 Proなどの端末に搭載
端末内で処理するため、追加料金なし
料金は地域や為替レートにより若干異なる可能性があります。また、Googleは無料利用枠を設けており、一定の使用量までは無料で利用できます。
企業向けのカスタムプランや大規模な利用については、個別に価格が設定される場合があります。
Geminiの料金体系は、モデルの種類や使用方法によって異なるため、具体的な用途に応じて最適なプランを選択することが重要です。
GeminiとBardの違いは?
GeminiとBardの主な違いは以下の通りです:
基盤技術:
Geminiは、Googleが新たに開発した最新の大規模言語モデルです。
Bardは当初LaMDA (Language Model for Dialogue Applications)をベースにしていましたが、現在はPaLM 2モデルを使用しています。
マルチモーダル能力:
Geminiはテキスト、画像、音声、動画などの複数のモダリティを同時に処理できる真のマルチモーダルモデルです。
Bardは主にテキストベースで、画像理解などの機能は後から追加されました。
パフォーマンス:
Geminiは多くのベンチマークでGPT-4を上回る性能を示しており、より高度な推論能力を持っています。
Bardは一般的なタスクには対応できますが、Geminiほどの高度な能力は持っていません。
利用可能性:
Geminiは現在、Google CloudやVertex AIなどの開発者向けプラットフォームで利用可能です。
Bardは一般ユーザー向けのチャットボットとして公開されています。
特化機能:
Geminiはコード生成や科学的推論などの複雑なタスクに特に強みがあります。
Bardは一般的な質問応答や文章生成に焦点を当てています。
更新頻度:
Geminiは最新のAI技術を反映して頻繁に更新されています。
Bardも定期的に更新されていますが、Geminiほど急速な進化はしていません。
言語サポート:
Geminiは多言語対応を強化しており、より多くの言語で高度な処理が可能です。
Bardも多言語対応していますが、言語によってパフォーマンスに差があります。
要約すると、GeminiはGoogleの最新かつ最も高度なAIモデルであり、マルチモーダル処理や複雑なタスクに優れています。一方、Bardは一般ユーザー向けのより親しみやすいチャットボットとして位置づけられています。GeminiはAIの最先端技術を反映しており、こちらを使用することをお勧めします。
Geminiは他の生成AIと比べてどんな性能?
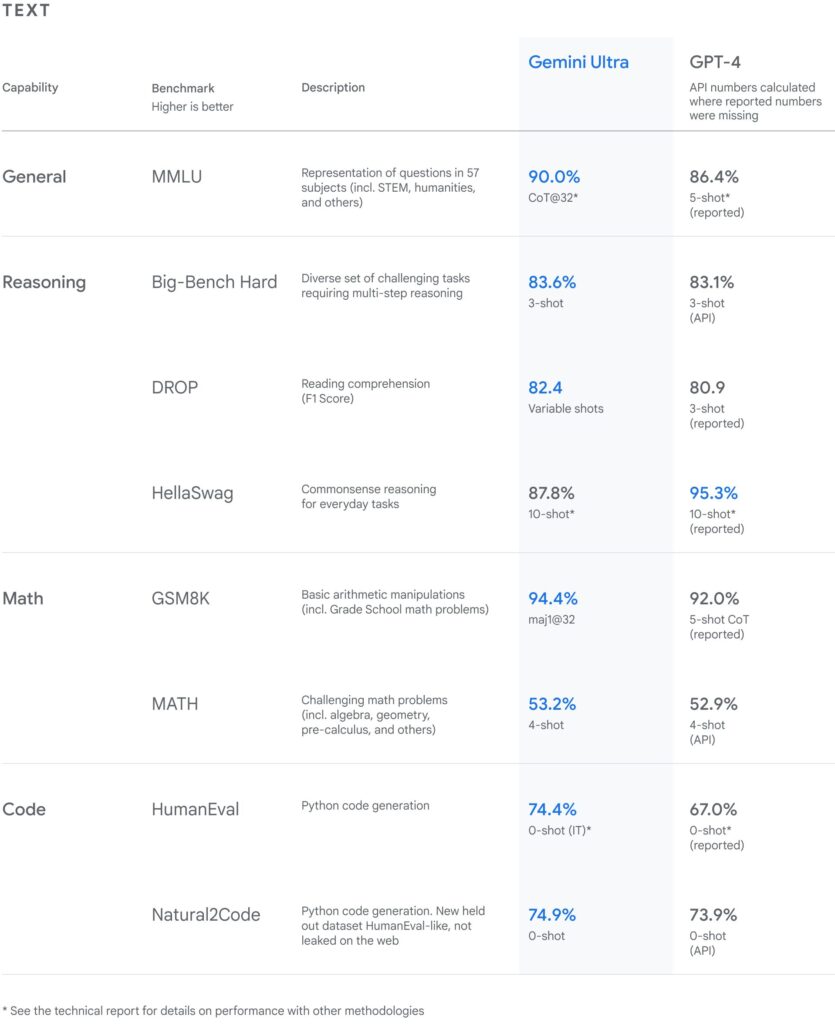
Geminiは、Googleが開発した最新の生成AIモデルであり、他の生成AIモデルと比較していくつかの顕著な特徴と性能を持っています。以下に、Geminiと他の主要な生成AIモデル(特にChatGPTやGPT-4)との比較を示します。
主な特徴と性能
マルチモーダル能力:
Geminiはテキスト、画像、音声、動画などの複数のデータ形式を同時に処理できる「マルチモーダル」モデルです。これにより、画像の解析、動画の要約、音楽の生成など、さまざまな形式のデータを統合して処理することが可能です。
GPT-4は主にテキストベースの処理に優れており、画像や音声の処理には別のモデル(例:DALL-E 2やWhisper)を使用します。
推論能力:
Geminiは高度な推論能力を持ち、複雑な問題解決や意思決定に優れています。特に、MMLU(Massive Multitask Language Understanding)ベンチマークで人間の専門家を超える性能を示しています。
GPT-4も高度な推論能力を持ちますが、特に常識的な推論や日常的なタスクにおいて優れています。
性能ベンチマーク:
Geminiは多くのベンチマークでGPT-4を上回る性能を示しており、特にマルチモーダルタスクや創造的な生成において優れています。
GPT-4は言語理解やテキスト生成において依然として強力であり、特に論理的推論や数学的問題において優れた性能を発揮します。
柔軟性と適応性:
Geminiはスマートフォンからデータセンターまで、さまざまなデバイスでスムーズに動作するよう設計されており、幅広い用途に対応できます。
GPT-4も多用途に対応できますが、特定のデバイスでの適応性については明示されていません。
実用的な応用:
Geminiは複雑なデータ分析やインタラクティブなコンテンツ生成など、マルチモーダルなタスクに適しています。
GPT-4は支援執筆やコンテンツ生成、テキストベースのユーザーインタラクションに理想的です。
結論
Geminiは、マルチモーダル処理能力と高度な推論能力により、特に複雑なデータ形式を扱うタスクや創造的な生成において優れています。一方、GPT-4は言語理解やテキスト生成において依然として強力であり、特に論理的推論や日常的なタスクにおいて優れた性能を発揮します。用途やニーズに応じて、どちらのモデルを選択するかが重要です。
テキスト生成ならGeminiに軍牌が上がり、GPTs機能などの使いやすさの点ではChatGPTが優れています。
Geminiが優れている点は?
Geminiは、他の生成AIモデルと比較していくつかの点で優れています。以下に、Geminiが他の生成AIより優れている主な点をまとめます。
1. マルチモーダル能力
Geminiは、テキスト、画像、音声、動画などの複数のデータ形式を同時に処理できる「マルチモーダル」モデルです。これにより、異なるデータ形式を統合して理解し、より複雑なタスクを実行することが可能です。例えば、画像の解析や動画の要約、音声の認識といったタスクを一つのモデルで処理できます。
2. 高度な推論能力
Geminiは高度な推論能力を持ち、複雑な問題解決や意思決定に優れています。特に、MMLU(Massive Multitask Language Understanding)ベンチマークで人間の専門家を超える性能を示しており、科学や金融などの分野での研究や調査において新たなブレークスルーをもたらすことが期待されています。
3. 創造的な生成能力
Geminiは創造的なテキスト生成においても優れており、特にクリエイティブな文章作成やコンテンツ生成において他のモデルを上回る性能を発揮します。これにより、マーケティングコピーや教育資料、ブログ記事などの作成が効率的に行えます。
4. コード生成と理解
Geminiは高品質なコード生成能力を持ち、複数のプログラミング言語でのコード生成や理解においても優れています。これにより、ソフトウェア開発の効率が向上し、開発者にとって非常に有用です。
5. リアルタイムデータの利用
Geminiはインターネットからリアルタイムでデータを取得し、それを基に応答を生成する能力を持っています。これにより、最新の情報に基づいた回答を提供することが可能です。一方、他のモデル(例:GPT-4)は事前に定義されたデータセットに基づいて訓練されており、最新情報の反映が遅れることがあります。
6. コスト効率
Geminiは、特に大規模なデータ処理においてコスト効率が高いとされています。例えば、入力トークンや出力トークンのコストが他のモデル(例:GPT-4)よりも低く設定されています。これにより、企業や開発者がより低コストで高度なAI機能を利用できるようになります。
まとめ
Geminiは、マルチモーダル処理能力、高度な推論能力、創造的な生成能力、コード生成と理解、リアルタイムデータの利用、そしてコスト効率の面で他の生成AIモデルよりも優れています。これにより、さまざまな分野での応用が期待されており、特に複雑なデータ形式を扱うタスクや最新情報を必要とするタスクにおいて強力なツールとなります。
テキスト生成に特化したい場合はGeminiを使おう!
Geminiは特にテキストの生成能力が高いです。ChatGPTと比べても、より自然な日本語で生成を行ってくれます。ですので、生成AIの用途として、記事作成や論文作成などのテキスト生成に重点が置かれているような方の場合は、Geminiの使用をお勧めします。

